


盘点!DeepSeek“开源周”



开源:未来的发展方向?

2月21日午间,DeepSeek在社交平台X发文称,从下周开始,他们将开源5个代码库,以完全透明的方式与全球开发者社区分享他们的研究进展。并将这一计划定义为“Open Source Week”。
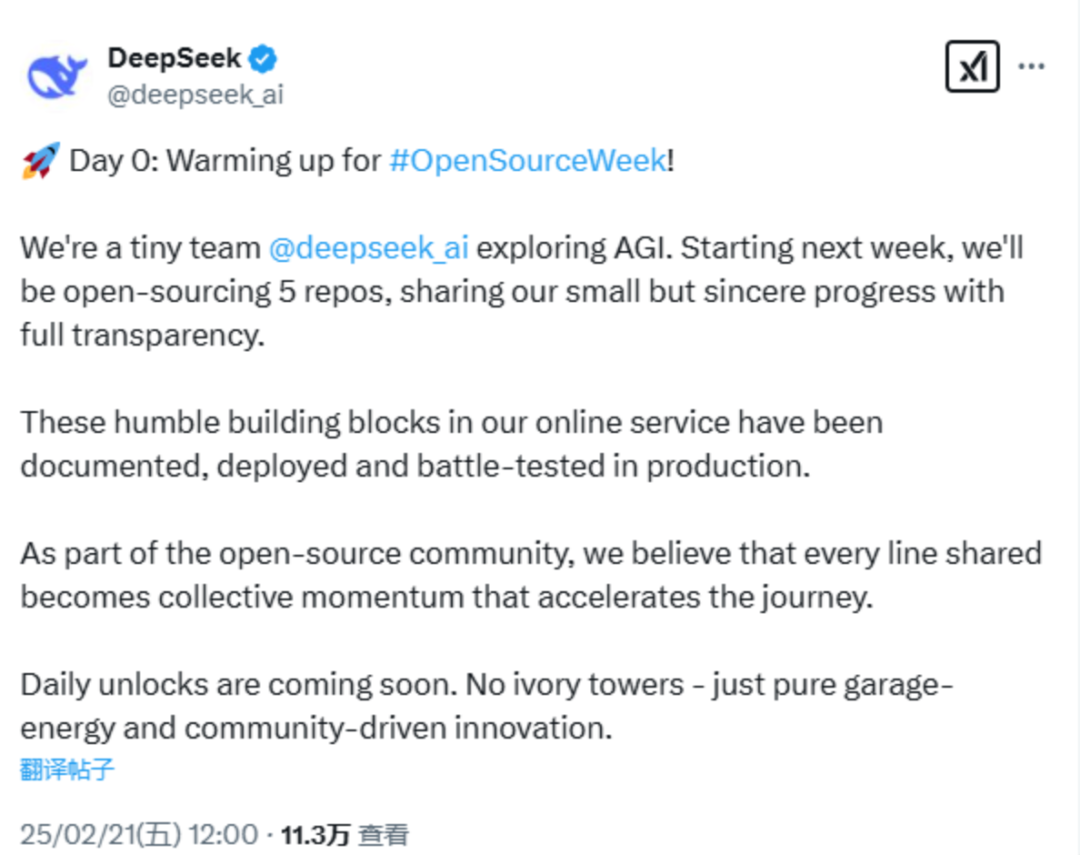
在最新发布的消息中,DeepSeek称:“我们是@deepseek_ai,一个致力于探索通用人工智能(AGI)的小团队。从下周开始,我们将开源5个代码库,以完全透明的方式分享我们虽小但真诚的进展。”
DeepSeek表示,即将开源的代码库是他们在线服务中的基础组件,且都经过了详细记录、部署和实战测试。
DeepSeek指出,作为开源社区的一部分,他们相信分享的每一段代码都将汇聚成集体力量,推动行业加速前进。“每日解锁的内容即将上线。这里没有象牙塔,只有纯粹的车库创业精神和社区驱动的创新。”
2月24日,DeepSeek启动“开源周”,开源了首个代码库FlashMLA。

据介绍,这是DeepSeek针对Hopper GPU优化的高效MLA解码内核,专为处理可变长度序列而设计,现在已经投入生产使用。“在H800上能实现3000 GB/s的内存带宽&580 TFLOPS的计算性能。”DeepSeek说。
简单来说,FlashMLA 是一个能让大语言模型在 H800这样的GPU上跑得更快、更高效的优化方案,尤其适用于高性能AI任务。这一代码能够加速大语言模型的解码过程,从而提高模型的响应速度和吞吐量,这对于实时生成任务(如聊天机器人、文本生成等)尤为重要。
MLA (Multi-Layer Attention,多层注意力机制)是一种改进的注意力机制,旨在提高Transformer模型在处理长序列时的效率和性能。MLA通过多个头(head)的并行计算,让模型能够同时关注文本中不同位置和不同语义层面的信息,从而更全面、更深入地捕捉长距离依赖关系和复杂语义结构。
此前,有从业者解析DeepSeek架构时提到,MLA的本质是对KV(Key-Value,一种缓存机制)的有损压缩,提高存储信息,“该技术首次在DeepSeek-V2中引入,MLA是目前开源模型里显著减小KV 缓存大小的最佳方法。”
继昨天开源Flash MLA后,DeepSeek25日向公众开源了DeepEP——第一个用于MoE模型训练和推理的开源EP通信库。

据介绍,DeepEP是一个用于MoE(混合专家)模型训练和推理的EP(Expert Parallelism)通信库,它为所有GPU内核提供高吞吐量和低延迟,也称为MoE调度和组合。该库还支持低精度操作,包括FP8。
同时,DeepEP针对NVLink(NVLink是英伟达开发的高速互联技术,主要用于GPU之间的通信,提升带宽和降低延迟)到RDMA(远程直接内存访问,一种网络数据传输技术,用于跨节点高效通信)的非对称带宽转发场景进行了深度优化,不仅提供了高吞吐量,还支持SM(Streaming Multiprocessors)数量控制,兼顾训练和推理任务的高吞吐量表现。
对于对延迟敏感的推理解码,DeepEP包含一组低延迟内核和纯RDMA,以最大限度地减少延迟。该库还引入了一种基于钩子的通信计算重叠方法,该方法不占用任何SM资源。
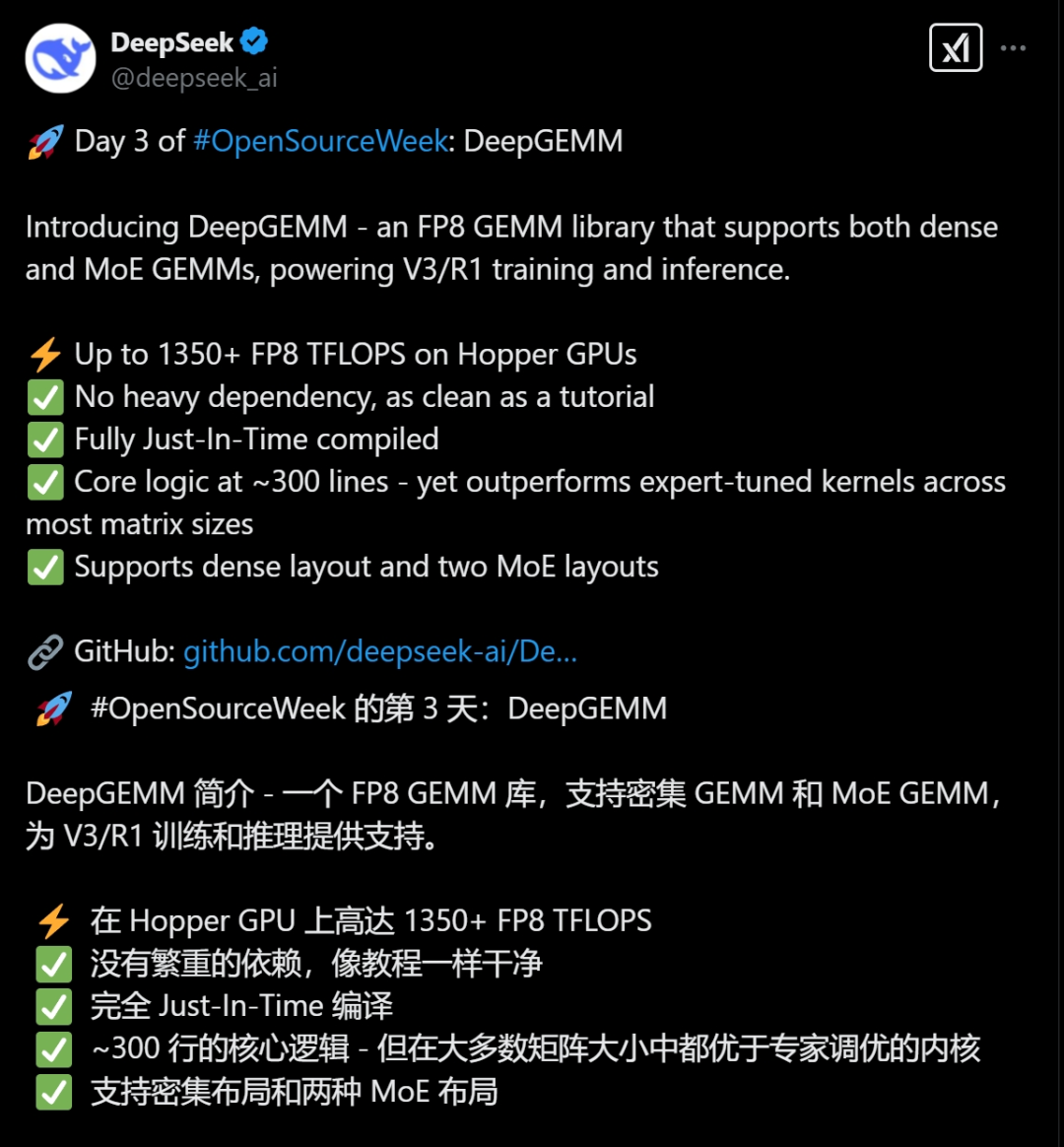
2月26日,DeepSeek宣布开源支持稠密和MoE模型的DeepGEMM(通用矩阵乘法)计算库,可为V3/R1模型的训练和推理提供强大支持。
 图片来源:X
图片来源:X
DeepGEMM最大的特点就是简洁高效,仅有300行核心代码。但在性能上,DeepGEMM的表现非常出色,在某些情况下甚至能够超越专家精心调优的计算库,可以说是极致榨干GPU的性能潜力。
 图片来源:X
图片来源:X
2月28日,DeepSeek开源周的最后一天,DeepSeek直接公开了V3和R1训练推理过程中用到的Fire-Flyer文件系统(简称3FS,第三个F代表File)和基于3FS和DuckDB构建的轻量级数据处理框架Smallpond。

图片来源:X
